The Global Scholar Awards proudly congratulate Dr. Sang-Hoon Park on earning the Best Researcher Award in Energy. This distinguished recognition celebrates outstanding dedication to scientific research, academic excellence, and innovative contributions that continue to strengthen the global energy research community and inspire future generations of researchers.
Dr. Sang-Hoon Park has demonstrated exceptional leadership through impactful research, advancing knowledge in energy science and promoting innovative technologies for a more sustainable future. This award acknowledges remarkable scholarly achievements, influential publications, and meaningful contributions that support scientific progress, environmental responsibility, and international academic collaboration.
Receiving the Best Researcher Award reflects Dr. Sang-Hoon Park's commitment to excellence, innovation, and lifelong research. The Global Scholar Awards proudly recognize these accomplishments and celebrate the lasting influence of this work on energy research, sustainable development, and the worldwide scientific community, encouraging continued excellence and discovery.
To understand true publication impact and influence patient outcomes, Medical Affairs teams must have their own benchmarks
Compass Points: The Future of Medical Affairs is a series exploring the strategic challenges facing Medical Affairs teams in today’s communication landscape—and the tools that will help them get it right.
The best publication strategy is like a treatment plan: bespoke
In the past, journal citations served as the primary metric for measuring publication impact. Citations all but guaranteed a share of voice and influence amongst key opinion leaders and healthcare practitioners; they were also a simple, clear metric to share upward, proving research impact and justifying the allocation of resources.
Today, journals have come to occupy a different place in the Medical Affairs community. They still confer legitimacy, but they’re not the only way to have an impact; they aren’t even necessarily the most appropriate channel through which teams can or should disseminate information.
How scientific information travels can be measured in both scientific impact and real world impact. Scientific impact comprises long-tail, more static measures such as citations and subsequent policy changes tracked over the course of months or years. But real-world impact—how a publication influences thought, conversation and even behavior—can be observed in how information ripples through other more immediate channels, like social or broadcast media and forums.
Capturing an accurate picture of how a publication has performed requires a view of both. This holistic view allows teams to accurately benchmark performance, measure impact, and demonstrate value to stakeholders, supporting the overarching goal of improving patient outcomes.
The role of the journal has changed
While journals still heavily inform the provision of healthcare alongside clinical guidelines and regulatory bodies, they are not the only place members of the life sciences community can encounter and learn about new research.
As scientific information has come to travel on more horizontal, peer-to-peer channels, such as social media or podcasts hosted by trusted key opinion leaders, practitioners are able to learn about and interact with new research outside of the journal publication and conference cycle. This makes it easier for HCPs to stay on top of relevant research, and to quickly sift through the studies that are relevant to their clinical practice. This is why, depending on the therapeutic area and the goals of a given publication launch, Medical Affairs teams may find they gain more traction by diversifying to non-traditional channels.
But in order for publication planners to take advantage of this reality—to optimize distribution across geographies, channels and a variety of timescales—requires dynamic, granular data that is consistently tracked through time. And as journals have come to form only part of the life sciences research diet, Medical Affairs teams have been left without a single, strategic reference point both for forward-planning and post-publication performance reporting.
As a result, teams find themselves in a familiar position: unable to reliably demonstrate impact, defend decisions to stakeholders, or to quickly iterate for later distribution plans. This can undermine a team’s efficacy, and ultimately delay or limit influence on patient outcomes.
What teams lose without a consistent benchmark
Benchmarking plays a critical role in publication planning. It allows teams to reference both the performance of earlier publications and the work of competitors, and to learn, in real time, what is working and what is not. Without benchmarks, it is impossible to know what is reasonable for research to achieve, and therefore, impossible to contextualize impact and prove a return on education.
But benchmarking is also one of the most laborious parts of the publication planning cycle. The process of consistently benchmarking, tracking, reconciling and cleaning point-in-time data—from social media, journals, podcasts, conferences, magazine articles, and more—can take teams weeks of work. And because of the fragmentation inherent to the process, all of this work, ultimately, still may not be able to capture the nuance of a publication’s impact.
The knock-on effect is that teams are unable to design strategies which are optimized for a given therapeutic area and to meet specific performance goals, such as social media engagement. This undermines the team’s ability to demonstrate that strategic objectives are met and can limit the diffusion of information into communities that could benefit from it.
This cycle repeats; without live, ongoing benchmarking, it’s impossible to see what’s changing in the competitive landscape and react to it.
In recent years, the Medical Affairs community has matured dramatically with regards to its use of data. Teams rely heavily on analytics and data-driven decision-making. They know what data is available to them and how they can use it to inform publication strategies.
But the tools available for assembling and parsing this data haven’t kept pace. Even as many teams embrace the use of general-purpose AI, the output is often unstandardized and non-reproducible—what AI surfaces today may be different from what it surfaces tomorrow, so teams can’t be sure they’re comparing like with like. In other words, teams gain speed, but not certainty.
This is what Compass by Dimensions was created to address. It brings together both traditional and alternative metrics so teams can easily benchmark against internal and competitor data, track publication performance through time and across channels in a standard and simple way, allowing to better demonstrate value, influence therapeutic behavior, meet education objectives, and trace real-world research impact. As a result, teams can move from publication strategies which are fundamentally reactive to those which are proactive, and as a result, better able to meet strategic objectives.
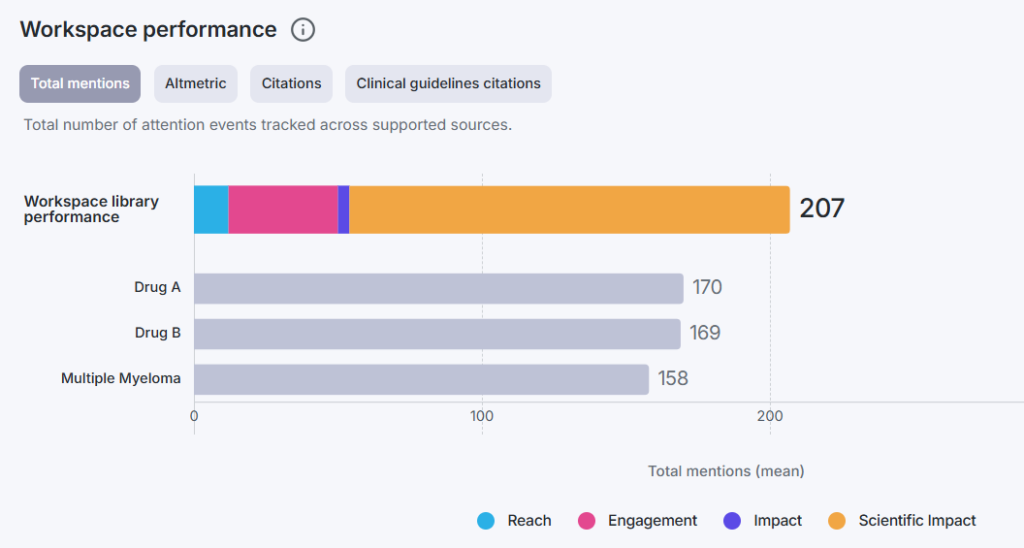
Figure 1: Workspace performance. Total number of attention events tracked across supported sources.
Tapping into the discussions that matter
Improving patient outcomes is the result of a confluence of events: research must be carried out, written up, disseminated, and then found by the relevant policy makers or healthcare practitioners to stand a chance of driving real-world impact. That means Medical Affairs teams need to look at both formal and peer-to-peer channels to measure influence.
Compass is driven by data sources from two leading services in the scientific and research community, Dimensions and Altmetric.
Dimensions hosts one of the largest collections of interconnected global research data, re-imagining research discovery with access to grants, publications, clinical trials, patents and policy documents all in one place. This data source provides a robust view of traditional channels.
Altmetric is a leading provider of alternative research metrics, helping everyone involved in research gauge the impact of their work. Altmetric searches thousands of online sources including social media, revealing where research is being shared and discussed—and the sentiment of that discussion. This is where real-world impact manifests first.
In bringing these two data sources together, Compass allows teams to track the whole publication attention lifecycle, from social media posts minutes and hours after publication, all the way to citations and guideline mentions years after it was published, all reliably benchmarked through time.
Teams need only set up a benchmarking dashboard to define which internal and competitor publications they want to track. Then the dashboard can be referenced any time for a simple view of a publication’s performance. Instead of the heavily manual work that teams had to endure before, Compass brings precise and consistent performance measurement and real-world benchmarking across assets or disease areas, giving teams the evidence needed to understand what’s working and where science is influencing practice.
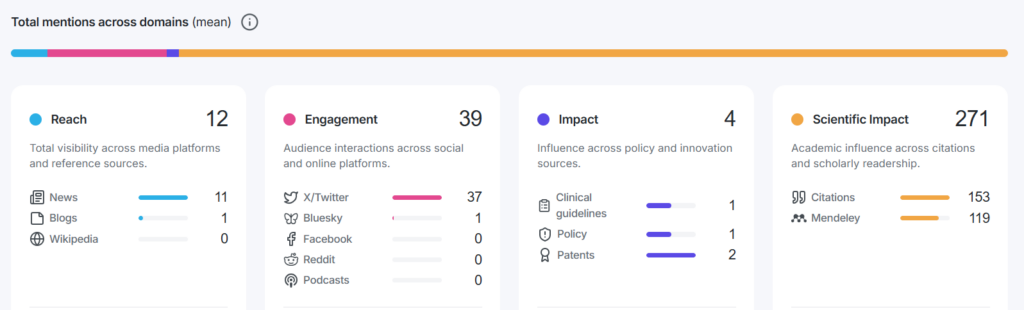
Figure 2: Total mentions across domains.
Democratizing data-driven publication strategy
Medical Affairs teams are too-often forced to rely on costly and slow agency relationships to understand how their publications are performing. Teams who can take these tasks in-house with tools such as Compass will amplify the efficiency and agility with which they can work.
Compass performs three functions which are critical to creating a truly bespoke, data-driven publication strategy
Unified, easy-to-reference metrics: Compass allows teams to quickly and consistently track performance through time to understand if a publication has reached the right people.
Custom benchmarking: Teams can benchmark publications against their own portfolio’s historical performance, establishing what a realistic result looks like. This exercise can also encompass competitors and specific therapeutic areas, helping teams identify opportunities and learnings. The task of surveying channels and creating internal and external benchmarks would have taken weeks before—now, once a dashboard is created, it takes just a few minutes to check.
Self-service interface: Compass creates shareable, stakeholder-ready visuals to clearly demonstrate the direct impact of work to decision-makers and support resource discussions with concrete data points. Teams can cut and re-cut data in a few minutes, saving the time, cost and hassle of looping in an agency every time a new report is needed.
Instead of waiting for an agency to return a report, or spending hours parsing data only for it to immediately stale, Compass places the power of real-time insights in the hands of the people best placed to wield it, streamlining the distribution process and supporting decision-makers with clear targets and performance measurement.
Use case: Moving from lagging indicators to real-time feedback
Take a mid-size oncology-focused biopharma preparing to launch a publication for a second-line therapy. The Medical Affairs team’s usual process might take three to four weeks per reporting cycle: they would need to pull citation counts from one system, social and news mentions from another, then manually reconcile both in spreadsheets. If socials spiked after review had concluded on a given platform, that data would be missed. This means by the time a report reached leadership, the data would already be stale, and there would be no consistent way to benchmark the publication against prior launches in the same therapeutic area, because citations move too slowly and social media moves too quickly.
For this team, Compass is designed to remove the manual burden of the benchmarking and tracking process. The team would first set up their benchmarking dashboard, tracking both the performance of previous portfolio publications and those of competitors working in specific therapeutic areas. Then, it would take just a few minutes to monitor performance: the team would easily be able to track journal citation activity against historical norms for the launch stage alongside engagement on clinician-focused social platforms and podcasts.
Teams would be able to see where the research was finding the most resonance and quickly take action on that basis, for example, redirecting a portion of dissemination budget towards channels demonstrating traction. The consistency of this data also makes it easy to keep leadership informed; teams can slice and share reports from their Compass dashboard to illustrate what’s working and what isn’t.
For teams that have previously relied on a single lagging metric, having a live, multi-channel benchmark can turn publication planning from a retrospective, best-guess exercise into a real-time, data-driven strategy.
The future of Medical Affairs is here—it’s time your strategy caught up
The proliferation of scientific information through popular channels is a good thing.
That new scientific and medical information can reach much wider audiences through a variety of channels undoubtedly has a net positive impact on patient outcomes. Patient and rare disease advocates, healthcare practitioners working in remote or underfunded areas, and even patients themselves all benefit from having access to the cutting edge science that will shape the future of medical care.
But the result of this proliferation has been a significant challenge for publication planners—no one could’ve predicted the rise of peer-reviewed podcasts. Now, teams need to take all of these data points into account when measuring performance and planning future publication launches.
Manually compiling point-in-time data is a time-intensive process that puts publications at a disadvantage and undermines strategic and patient outcome objectives.
The right strategy is one entirely specific to a given publication—it must be tailored to relevant journals, audiences and channels, and these may all change through time. To date, with this level of nuance, it wasn’t possible for teams to keep up—not at the level of granular detail that could shape truly powerful publication strategies.
Compass turns that complexity into an opportunity.
Congratulations to Assoc. Prof. Dr. Noura Al-Dayan on receiving the Innovative Research Award in Medical Laboratory at the Global Scholar Awards. This prestigious recognition honors her exceptional research achievements, scientific innovation, and unwavering commitment to advancing medical laboratory sciences through impactful discoveries that contribute to improved healthcare, diagnostics, and biomedical research worldwide.
The Innovative Research Award recognizes researchers whose work demonstrates originality, academic excellence, and meaningful scientific contributions. Assoc. Prof. Dr. Noura Al-Dayan has consistently advanced the field of Medical Laboratory through high-quality research, interdisciplinary collaboration, and dedication to developing innovative approaches that strengthen healthcare and scientific knowledge.
The Global Scholar Awards proudly celebrates Assoc. Prof. Dr. Noura Al-Dayan for her remarkable accomplishments and lasting impact on the scientific community. This well-deserved recognition reflects her passion for research, commitment to excellence, and continued efforts to inspire innovation, collaboration, and future advancements in medical laboratory science.
What does responsible research assessment actually ask of the people who build the infrastructure, rather than those who write the policy? In this post, Steven Hill traces the arc from DORA and the Leiden Manifesto through to the Barcelona Declaration, and sets out what the principles mean in practice for the tools that describe, discover, and measure research.
More than a decade ago, one of my first tasks in a new job was to advise on whether the organisation I had just joined, the Higher Education Funding Council for England, should sign the San Francisco Declaration on Research Assessment (DORA). We did, as a founding signatory, and it was the right decision. DORA’s central claim is that metrics, especially the journal impact factor, should not stand in as a proxy for the quality of an individual piece of research. As well as being right, that principle was an important signal that the UK’s national research assessment process was not taking a reductive approach to research quality.
What has stayed with me from that period is not the signing, but what came after. Alongside committing to an expanding set of principles building on DORA, the research system needs the patient work of turning those principles into reality. The Metric Tide, and its follow up seven years later, were in large part an attempt to take that problem seriously, and coined the term ‘responsible research assessment’, which labels the movement. The arc from DORA through the Leiden Manifesto, the Metric Tide, the Hong Kong Principles, the Coalition for Advancing Research Assessment (CoARA), and, most recently guidance from the Global Research Council (GRC), is the story of the global research community moving from declaration to implementation. The GRC, which brings together the heads of science funders from around the world, has provided funders with both tools to assess their own performance and a practical guide to making the changes needed in their practice. And the SCOPE framework for research evaluation offers a process for thinking through responsible research assessment in any evaluation context.
I find myself thinking about all of this again, but from an unfamiliar direction. For most of my career I have been a policy-maker, writing the principles and fretting about whether anyone is following them. At Digital Science I now look from a different direction: the building of the tools through which research gets described, discovered, and measured. Both setting the policy environment and helping to shape the tools bring power and responsibility, but the potential and the pitfalls are different. The shift in vantage point raises a question: what should responsible research assessment ask of the people who build the infrastructure?
What the Principles Ask For – and What They Don’t
It is worth being clear about what responsible research assessment is, because it is easily caricatured. It is not a rejection of measurement, and it is not a plea to return to pure peer review uninformed by data. Read across DORA, the Leiden Manifesto, the Metric Tide, the Hong Kong Principles, and the CoARA agreement, and a consistent core emerges. Assessment should rest primarily on qualitative, expert judgement, with peer review at its heart, supported, not supplanted, by the responsible use of quantitative indicators. It should judge the work rather than the venue it appeared in. It should recognise the genuine diversity of what researchers produce and do: not only papers, but data, software, mentoring, peer review, public engagement, the often invisible labour of the people who make research possible. And it should be sensitive to context, to discipline, to career stage, and honest about its own limitations. Finally, as emphasised by the SCOPE framework, it is also important to critically reflect on whether evaluation is needed at all.
It is also fair to say that commercial entities in the research evaluation space are often criticised in discussions about responsible research assessment. The Leiden Manifesto asks that the data and the methods behind indicators be kept open and transparent, so that those being evaluated can verify them. CoARA goes further, calling for the research community to retain ownership and control of the infrastructure and the criteria used to assess it, and is openly wary of proprietary “black boxes”. The most recent Metric Tide review is blunt about the harm that commercial university rankings—built outside the academic community—continue to do to research culture.
Some of these critiques can be valid, although there are real practical challenges in realising total community ownership of data and infrastructure. And comparative analytics, well constructed and appropriately used, have a place in benchmarking universities. There is also the question of how commercial providers respond to responsible research assessment. The tools and the data are not going away; the question is whether they pull in the direction of the principles or against them. That is the real issue, and it should be the focus of the people who build the infrastructure, whether commercial or not, alongside the people who write the policies.
Why Openness Comes First
At Digital Science, colleagues here have been wrestling with this in public, through the lens of the Barcelona Declaration on Research Information. The Declaration’s first commitment is to make openness the default for the research information we use and produce—the records of who did what, where the money went, how outputs and contributions connect to one another—and to support the shared, open infrastructures that hold it. Writing on this blog, our CEO Daniel Hook has made the case that researchers have a fundamental right to access the metadata about research, and that the data used to evaluate academics should be transparently available and reproducible. He also argues that there are questions of assessment and measurement that will need data that is costly or complex to collect, and that openness might not be possible in this case. I think considering the balance and tension is the right direction, and it is worth dwelling on why, because open research information is the hinge on which the whole argument turns.
The responsible-metrics principles are simply not achievable on top of closed, unverifiable information. You cannot ask people to trust an assessment built on data they are not allowed to see. Open research information is the precondition, not an optional extra. But openness on its own is not enough. My colleague Simon Porter has written, again on this blog, about our responsibilities as consumers of metadata, not just producers of it. Use of research information needs to take into account the context in which it was generated, its provenance, and the extent to which the sources of information can be trusted, not just its availability. Information that is not accurate or appropriately contextualised can disrupt human judgement rather than support it. Simon also rightly notes potential equity concerns, where the metadata rich get privileged over the metadata poor, undermining the diversity and inclusion principle inherent in responsible assessment. He also notes that, as well as the responsible use of research information, responsible collection of data is also important.
Putting Principles into Practice
How does a commercial research infrastructure provider understand its role in supporting responsible research assessment? Rather than consider Digital Science’s products one by one, I want to focus on the principles of responsible research assessment and highlight examples where our tools and other options are aligned.
Broadening what counts. Research is more than journal articles, and the infrastructure has to be able to see and recognise a broader range of outputs. Being able to give a dataset a persistent identifier and a home, to surface software and preprints and policy documents alongside papers, to connect grants and patents and clinical trials into a fuller picture of a contribution is at the heart of responsible assessment. Digital Science tools such as Symplectic Elements, Figshare, and Dimensions, and the tools and work flows that they enable, are useful here precisely to the extent that they make the diverse outputs visible and creditable.
Supporting judgement rather than replacing it. The most valuable thing a system can do is not to produce a number, but to assemble as broad a view of the available evidence, so that human beings can exercise judgement well, and a researcher can tell their own story. Dimensions includes a range of tools that enable decision-makers to access clear summaries of the data and evidence that they need. Research information systems, such as Elements, that support narrative and evidence-based CVs, and that spare people the indignity of re-keying the same information into yet another form, are doing something genuinely in the spirit of the reform. The recently introduced CV import capability in Elements contributes directly to this objective.
Many dimensions, not one. When Altmetric first appeared, its real purpose was not to provide a new “score” but to emphasise evidence of broader contributions beyond those measured through citations. Evidence of attention in policy documents, in the press, in clinical guidance tells you something a citation count cannot. Links between publications and patents and policy documents in Dimensions also provide this richer picture of research. Outside of the Digital Science product line, Overton also provides data on the rich connections between research and policy.
Transparency and context. This is where the Barcelona Declaration is important, and Digital Science’s Open Principles set out how we work to align our tools with its aims. Making core elements of the Dimensions and Altmetric datasets freely available sits at the heart of these principles, alongside our commitments to work with the research community, and to openly publish our thinking and research. For example, where Dimensions data are used for assessment purposes researchers and their employers can check and verify the data. Our data sits alongside other open sources such as Crossref and DataCite and persistent identifiers like ORCID and ROR, key parts of the open responsible research assessment infrastructure. OpenAlex also offers fully open information as a secondary aggregator, overlapping in some areas with Dimensions.
I have spent enough time on the policy side to be wary of believing that any of this can be solved by better tools alone. Responsible research assessment is about behaviours, norms and incentives as much as it is about systems and infrastructure. And the choice isn’t between commercial infrastructure and community-owned systems. What matters is that infrastructure is built and used in a way that supports human judgement, broadens what we value, and submits itself to transparency and scrutiny. This is what responsible research assessment asks of those who build the infrastructure, and should inform everything we do at Digital Science.
Congratulations to Assist. Prof. Dr. Yujing Yang on receiving the Best Researcher Award in Engineering. This prestigious recognition celebrates your exceptional research excellence, academic dedication, and meaningful contributions to advancing engineering innovation.
Your pioneering research, commitment to scientific discovery, and passion for excellence continue to inspire fellow researchers and strengthen the global engineering community. Your achievements reflect outstanding leadership and scholarly distinction.
May this remarkable accomplishment open new opportunities for collaboration, innovation, and continued success. Wishing you a future filled with groundbreaking discoveries, professional growth, and lasting impact on engineering and society.
Congratulations on this prestigious recognition for your outstanding research and innovative contributions. Your achievement is a testament to your dedication and excellence.
.png)




